Načtení dat popisujících rovnováhu z Excelu a textového souboru, jejich zobrazení v grafu.
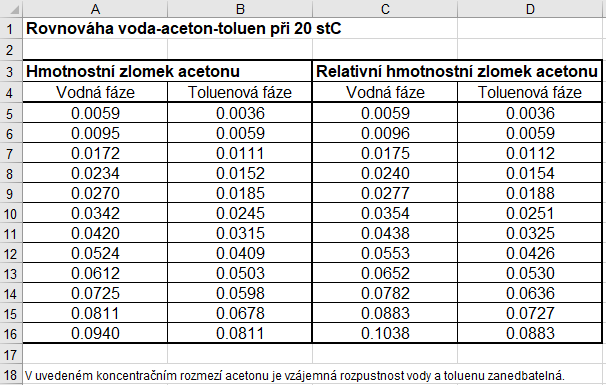
Načtení dat z externích souborů do Pythonu je ukázáno na příkladech textového souboru a Excelu. V obou případech využijeme data k rovnováze voda–aceton–toluen při teplotě 20 °C dostupné v E-tabulkách. Soubor v Excelu vypadá následovně:
Stažený soubor je vhodné umístit do stejného adresáře, v němž je uložen Python skript, jehož prostřednictvím budeme soubor načítat, případně je možné umístit jej do složky v tomto adresáři. Pro načtení Excel souboru využijeme balíček Pandas, přestože variant pro načítání je více. Pro volání balíčku Pandas si na začátku kódu definujeme alias pd následovně:
import pandas as pdPoté si můžeme definovat cestu k souboru. Pokud je uložen ve stejném adresáři jako Python kód stačí příkaz s názvem souboru:
filename='voda-aceton-toluen.xls'Jestliže jsme uložili Excel soubor v adresáři do složky data, definice cesty k souboru vypadá následovně:
filename='data/voda-aceton-toluen.xls'Nyní přejdeme k samotnému příkazu pro načtení dat. Budeme používat příkaz read_excel se specifikací názvu našeho souboru. Načtená data si rovnou přiřadíme do proměnné data:
data = pd.read_excel(filename)Nyní si můžeme ověřit, jak vypadají data, která jsme načetli pomocí jejich vypsání:
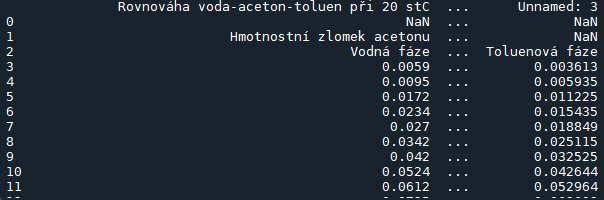
print(data)Část výpisu tohoto příkazu je zobrazena na přiloženém obrázku. Můžeme vidět, že je načteno vše včetně nadpisu, prázdných buněk a prázdných řádků.
My bychom chtěli omezit načtení pouze na hodnoty zlomků a hlavičky jednotlivých sloupců. Toho lze dosáhnout specifikací argumentů příkazu read_excel. Konkrétně využijeme argumenty skiprows a skipfooter, kterými definujeme, kolik řádků vynecháme shora a kolik zdola. Pro náš případ volíme hodnoty následovně:
data = pd.read_excel(filename, skiprows=3, skipfooter=2)Další možnosti argumetů jsou k dohledání v dokumentaci. Pro ověření správného načtení je opět možné vypsat data pomocí příkazu print.
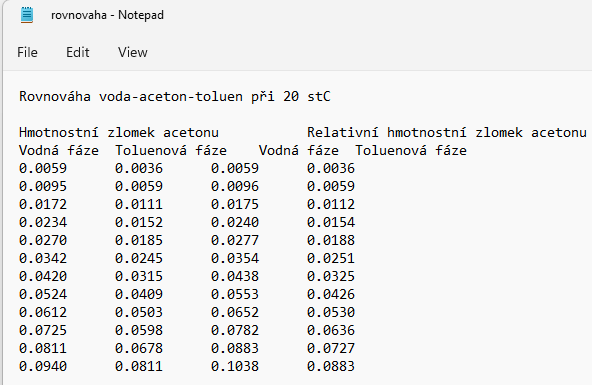
Pro načítání dat ze souborů s příponou .txt je postup pomocí balíku Pandas velmi podobný. Opět jsou zde alernativy jako například příkaz loadtxt z balíku NumPy. Prozatím zůstaneme u balíku Pandas. Vzorový textový soubor rovnovaha.txt, který jsme uložili do skožky data v adresáři, v němž je uložen Python kód, vypadá následovně:
Definujeme název načítaného dokumentu například do proměnné filename a načteme data tentokrát příkazem read_csv:
filename = 'rovnovaha.txt'
data = pd.read_csv(filename,sep='\t', skiprows=3)Argument sep=’ říká, že data jsou v textovém souboru oddělena tabulátorem, a již známým argumentem skiprows definujeme přeskočení prvního řádku při čtení. Nyní máme hodnoty načteny pod proměnnou data a můžeme s nimi dále pracovat.
Jako první se nabízí načtená data vykreslit do grafu. Pro tvorbu grafů budeme používat balík Matplotlib. Nejprve si tedy definujeme proměnnou plt pro funkce Pyplot z balíku Matplotlib:
import matplotlib.pyplot as pltPokud máme připravené hodnoty pro tvorbu grafu, jako bylo popsáno v předchozích kapitolách, můžeme přejít k tvorbě grafu pomocí následujících příkazů:
plt.plot(data['Toluenová fáze'], data['Vodná fáze'], marker="o", linestyle='None')
plt.xlabel("Zlomek toluenové fáze (-)")
plt.ylabel("Zlomek vodné fáze (-)")
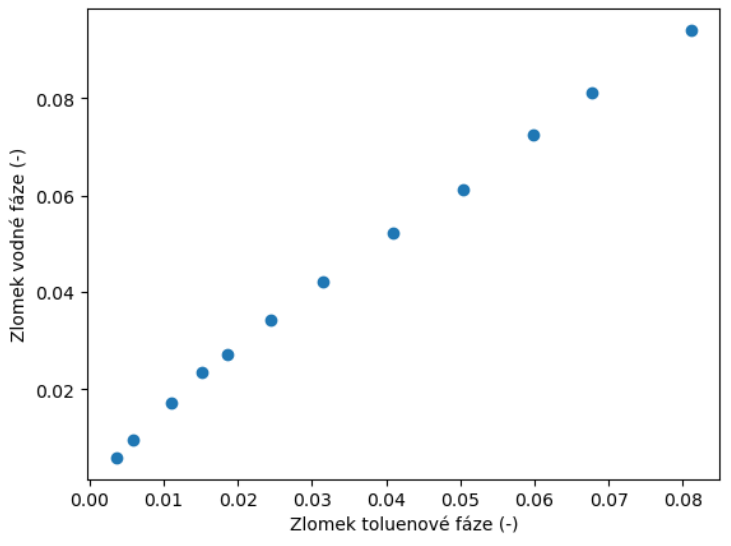
plt.show()Pomocí příkazu plt.plot definujeme popořadě x-ové a y-ové hodnoty pomocí dříve definované proměnné data a názvu daného sloupce v hranaté závorce. Dále v argumentu příkazu plt.plot speficikujeme tvar vykreslovaných bodů (marker) a druh čáry, která tyto body spojuje (linestyle). V našem případě prozatím nechceme spojení bodů čarou, proto volíme možnost None. Na dalších dvou řádcích definujeme názvy os a posledním řádkem voláme zobrazení grafu. Všimněte si, že symboly ’ a ” jsou zaměnitelné. Námi definovaný graf vypadá takto:
Pokud bychom chtěli náš graf uložit zaměníme příkaz plt.show() za následující příkaz, kde definujeme název souboru a jeho formát:
plt.savefig("rovnovaha.png") Do grafu můžeme přidat další datové řady a upravit jej dle preference například přidáním legendy, mřížky, názvu grafu nebo definicí rozmezí vykreslovaných hodnot na obou osách:
plt.plot(data['Toluenová fáze'], data['Vodná fáze'], marker="o", linestyle='None', label="Absolutní zlomky")
plt.plot(data['Toluenová fáze.1'], data['Vodná fáze.1'], marker="o", linestyle='None', label="Relativní zlomky")
plt.legend(loc = 'upper left')
plt.title('Rovnováha toluen-voda')
plt.xlabel("Zlomek toluenové fáze (-)")
plt.ylabel("Zlomek vodné fáze (-)")
plt.xlim([0, 0.1])
plt.ylim([0, 0.12])
plt.grid(color='grey', linestyle='--', linewidth=0.5, alpha=0.7)
plt.show()
Více možností pro úpravu grafů je k dohledání v dokumentaci. Doposud jsme pracovali s načtenými daty ve formě sloupců, tak jak jsou v původních dokumentech. Pokud by při další práci s daty byl tento formát na obtíž, je možné změnit formát dat například na list, data v tomto formátu přiřadit k proměnným a pod těmito proměnými je vykreslit nebo s nimi jinak pracovat:
uA = list(data["Vodná fáze"])
wA = list(data["Toluenová fáze"])
UA = list(data["Vodná fáze.1"])
WA = list(data["Toluenová fáze.1"])
plt.figure()
plt.plot(wA, uA, marker="o", linestyle='None', label="Absolutní zlomky")
plt.plot(WA, UA, marker="o", linestyle='None', label="Relativní zlomky")
plt.legend(loc = 'upper left')
plt.title('Rovnováha toluen-voda2')
plt.xlabel("Zlomek toluenové fáze (-)")
plt.ylabel("Zlomek vodné fáze (-)")
plt.show()import pandas as pd
import matplotlib.pyplot as plt
filename='data/voda-aceton-toluen.xls'
data = pd.read_excel(filename, skiprows=3, skipfooter=2, sheet_name="List1")
print(data)
plt.plot(data['Toluenová fáze'], data['Vodná fáze'], marker="o", linestyle='None', label="Absolutní zlomky")
plt.plot(data['Toluenová fáze.1'], data['Vodná fáze.1'], marker="o", linestyle='None', label="Relativní zlomky")
plt.legend(loc = 'upper left')
plt.title('Rovnováha toluen-voda')
plt.xlabel("Zlomek toluenové fáze (-)")
plt.ylabel("Zlomek vodné fáze (-)")
plt.xlim([0, 0.1])
plt.ylim([0, 0.12])
plt.grid(color='grey', linestyle='--', linewidth=0.5, alpha=0.7)
plt.show()import matplotlib.pyplot as plt
import pandas as pd
filename = 'rovnovaha.txt'
data = pd.read_csv(filename,sep='\t', skiprows=3)
print(data)
plt.plot(data['Toluenová fáze'], data['Vodná fáze'], marker='o', linestyle='none', label='Absolutní zlomek')
plt.title('Rovnováha toluen-voda')
plt.xlabel("Zlomek toluenové fáze (-)")
plt.ylabel("Zlomek vodné fáze (-)")
plt.xlim([0, 0.1])
plt.ylim([0, 0.1])
plt.grid(color='grey', linestyle='--', linewidth=0.5, alpha=0.7)
plt.legend()
plt.show()